
创新工场南京人工智能研究院执行院长冯霁做客雷锋网AI金融评论公开课,以“浅析联邦学习中的安全性问题”为题,详尽地讲解了联邦学习的特点、联邦学习的应用和安全防御对策等内容。
以下为冯霁演讲全文内容与精选问答:
今天跟大家简单的汇报,我们对联邦学习中安全性问题的思考。

在介绍联邦学习之前,先简单介绍一下创新工场中国机械网okmao.com。
创新工场,是由李开复博士在2009年创办的创投机构,经过10余年的发展,在国内外都颇具影响力。
创新工场的特色之一是设立了创新工场人工智能工程院,开创了独特的VC+AI模式。创新工场人工智能工程院最近针对人工智能系统的安全性和隐私保护方向,做了一点自己的思考,今天和大家做一个简要的技术上的分享。
人工智能系统的安全性问题
这一波(2015年后)人工智能的兴起,使得人工智能逐渐从低风险的应用,比如判断一封邮件是否是垃圾邮件,转向了高风险应用,比如自动驾驶、无人机、还有重度依赖人工智能技术的金融投资、投顾等领域。

一旦这些人工智能系统出现了偏差甚至错误,它所带来的损失不仅仅是巨额的财产,还有可能是生命。
但是,一个核心的问题是,人工智能领域涉及到的安全问题,和传统的软件工程安全问题,是否存在本质的不同?我们能否继续使用传统的攻防工具,对人工智能系统进行安全分析?
这就需要谈到软件1.0和软件2.0的概念。
我们认为在这一轮的人工智能兴起之后,整个软件工程也产生了一个范式的转变。
在传统的软件工程中,工程师会搭建一个系统,构建一个基于规则的程序,输入数据后,计算机会给出确定性的输出。这是软件1.0时代的特征。
而随着这一波人工智能的兴起,诞生了一个新的软件工程开发范式,程序是由数据驱动的方式,利用人工智能算法自动产生的,这从软件工程角度来看,是一个相当本质的改变,有人称之为软件2.0时代。

因此,在软件工程1.0时代的一系列安全分析,漏洞分析的手段,到了软件2.0时代不再适用。软件工程范式的改变,带来了全新的安全问题。
目前针对人工智能系统的攻击,可以分成两大类。一类是测试阶段攻击,一类是训练阶段攻击。
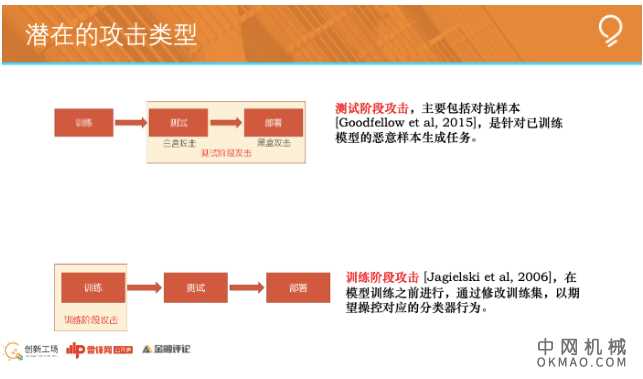
测试阶段攻击
训练阶段攻击发生在AI模型训练之前,测试阶段攻击针对是已训练好的AI模型。我们先看测试阶段攻击。
测试阶段的攻击,大家见的最多的一类,也对抗样本。

左边的这张图拍的是大熊猫的照片,当攻击者知道这个图像分类模型的所有参数后,就可以根据模型的参数,精心设计出干扰“噪声”(中间的图)。
把噪声叠加在左图,形成右图。虽然我们用肉眼看到的右图和左图一模一样,但图像分类模型会把右图的熊猫错认为另一种生物。这个过程就是所谓的对抗样本攻击。
对抗样本不仅仅可用于电脑储存的数字图像,还可以应用在真实的物理环境中。
比如对交通的路牌做微小的改动,就可能让自动驾驶汽车在行驶过程中因为不能正确识别,而做出错误的行动。再比如用3D打印技术设计出一只乌龟,在乌龟的纹理上做对抗样本的叠加,模型会认为这是一个其他物种。
对抗样本并不神秘,学术界认为它攻击原理的本质就是由于我们的输入样本在一个非常高维的空间中。而通过机器学习模型学习出来的决策边界,在高维空间中是高度非线性的。

对抗样本在这些高度非线性的角色边界附近产生了一个扰动,扰动就会让模型从分类一误判为分类二(如上图)。但它们在视觉上很难区分。
刚才讲的对抗样本,从另一个角度来看,是白盒攻击。意思是攻击者需要提前知道AI模型的所有参数信息。
黑盒攻击,是另一种测试阶段攻击,攻击者对指定模型的参数未知,只知道模型的输入输出,这种情况下依旧想产生特定的对抗样本,很明显黑盒攻击的难度更大。
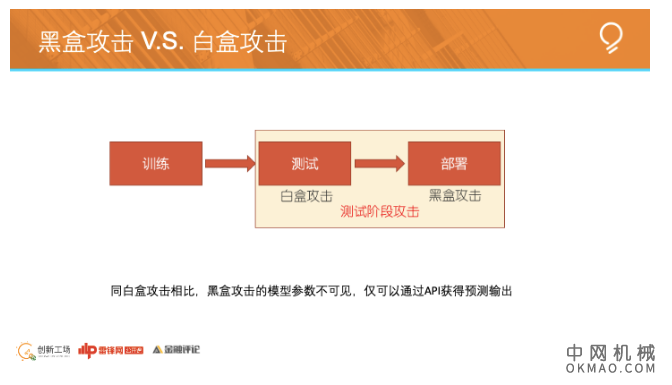
怎样才能让黑盒攻击,做到和白盒攻击一样的效果呢?对此,目前常见的攻击思路有两大方向:
黑盒攻击的第一大方向,是利用对抗样本的普适性。
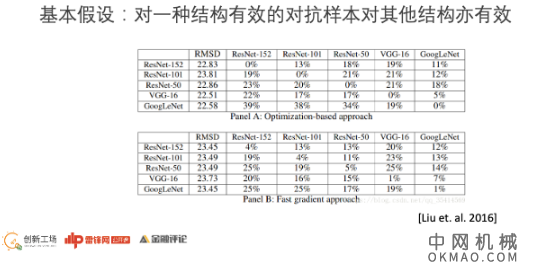
虽然准备攻击的对象的模型和参数不知道,但是我们可以找一个已知的模型,比如说VGG,或者ResNet(残差网络),来做一个对抗样本。
我们的核心假设是如果这个对抗样本能哄骗已知的模型,也就能哄骗云端(黑盒)的分类器, 2016年有人做过一个的工作,用不同的神经网络架构产生相应的对抗样本,去哄骗其他的结构。实验的结果证明了,这个假设是合理的。
怎样加强这种对抗样本的普适性?

首先是在训练替代模型时,对数据进行增广,其次是利用集成方法,如果它能成功的攻击多个已知的白盒的模型的集成,那么攻击一个黑盒的API,成功率就会高一些。

黑盒攻击的第二个方向,是基于查询的逆向猜测,目前有一些云服务,返回时显示的不仅仅是一个标签,还包括了某一个类别的概率的分布的向量。
这个分布向量包含了关于模型本身非常多的知识。我们可以让这个模型标注足够多的样本,然后训练一个本地模型,模拟云端模型的行为。由于本地模型是白盒的,利用现有白盒攻击算法,针对本地模型产生对抗样本,再由于普适性,该样本对云端黑盒模型往往同样有效。
这件事情的关键,是训练一个本地的模型,该模型能够模仿黑盒模型的行为。有点像吸星大法。学术界Hinton等人提出的知识蒸馏,以及更早的周志华教授提出的二次学习,本质都是在干这件事情。
我们也可以用遗传算法,改变输入样本的像素的值,每次改变一点点,就访问一下云端的API。用这种方式,我们就能慢慢地收到一个可以哄骗云端的对抗样本。
训练阶段攻击
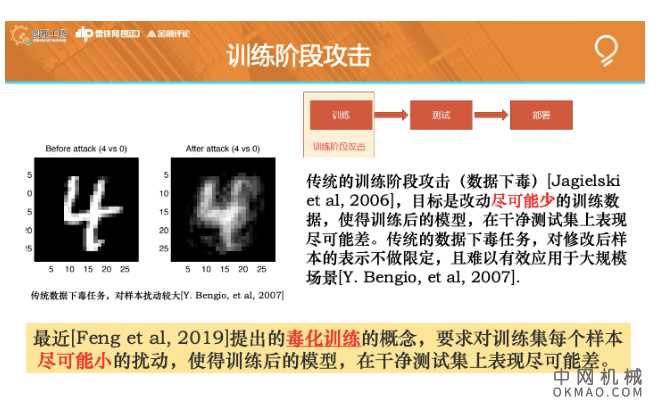
刚刚讲的,是测试阶段攻击。下面讲,训练阶段攻击。